Backing up Universal Analytics data in BigQuery
No point kicking up a fuss about it now, Universal Analytics (UA) is on life support. It still contains all the data but is not collecting more (well, in theory). In another year, the lovely historical information you collected over many years will also be on the chopping block. If you were not an early adopter of GA4, that could mean you lack the ability to perform any meaningful year-on-year analysis – for another year, anyway.
Perhaps you were lucky enough to have Universal Analytics 360 and had all your data backed up in BigQuery from the get-go. However, for many, 360 was/is not an option financially.
Perhaps you use an off-the-shelf ETL pipeline solution to back up your data (Supermetics, Funnel, Skyvia). But again, these can be expensive and a bit of an unwanted monthly outgoing for this single-use case.
This is why, here at Measurelab, we saw an opportunity to build a tool for our clients that will let them back up as many UA reports as they wish, as far back as they dare and store all that data in BigQuery for as long as they need it.
Enter the incredibly creatively named “Universal Analytics to BigQuery Backfill… tool”!
A little background
When Measurelab took up the task of creating a backfill tool for UA data in BigQuery, we went a little against the grain. We discarded the idea of a complete backup of UA data. Why? Well, depending on your traffic levels, it could be costly, both from a data processing and storage perspective. Another reason is we believe you need only backup data pertinent to your performance indicators. Why import row after row of data on the operating system of a user when it is of no interest to your business? It is a valuable exercise to sit down and really think critically about what data you actually need, not analytics for analytics’ sake. For this reason, we built a tool that collects data based on user-defined reports. Just specify your metrics, dimensions and your date range and away you go.
The nuts and bolts of the tool
The tool is a Flask application hosted on App Engine. It also uses Cloud Tasks to shatter API requests into daily chunks, Cloud Functions to make API calls, and BigQuery to store all the data. Engineering this solution on the Google Cloud Platform helps dodge sampling issues and keeps a lid on the API load to prevent quota limits from being breached. It also allows us to dynamically scale to meet the needs of the requests being received.
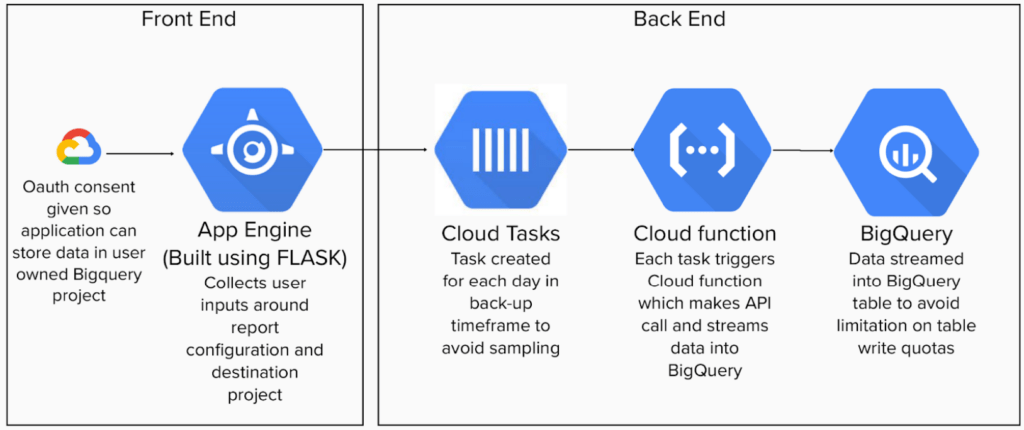
Flask and App Engine
App Engine is Google’s fully managed, serverless platform for developing and hosting web applications. Flask, a micro web framework written in Python, has been utilised with App Engine to manage the tool’s web requests and responses.
The primary responsibility of the App Engine and Flask setup is to accept user-defined report configurations. The configurations are parsed, and the necessary API requests for data retrieval are created. These requests are then broken down into daily chunks, enabling the handling of large data sets without overloading the system or hitting sampling issues.
Cloud Tasks
Cloud Tasks is a fully managed service that allows developers to manage the execution, dispatch, and delivery of a large number of distributed tasks. Within the context of this tool, Cloud Tasks works to ensure that each API request is correctly undertaken. It can be configured only to run a certain number of tasks at the same time which allows for a controlled load on the API, avoiding quota limits.
By leveraging Cloud Tasks, the tool manages to execute each request reliably and efficiently, even in the event of temporary API outages or system failures, as Cloud Tasks have a built-in system for retrying failed attempts. Each task is a trigger for our cloud function.
Cloud Function
Cloud Functions, Google’s event-driven serverless compute platform, comes next in the pipeline. It’s designed to scale up in response to internet events and triggers.
In the case of this tool, the Cloud Functions’ primary role is to process the daily chunks of API requests received from the Cloud Tasks. They manage the asynchronous execution of these requests, ensuring a smooth, continuous data flow, even with sporadic internet or system interruptions. The function creates and then streams the data into a BigQuery table. Streaming allows for much higher rates of table writes, something that is necessary when dealing with large backfills of data.
The bottom line
We’ve designed our tool to effectively address the limitations associated with Universal Analytics, particularly its lack of a native BigQuery data transfer service. Utilising Google App Engine, Cloud Functions, and Cloud Tasks, our tool facilitates a user-configurable, reliable, and cost-effective method for backing up crucial data to BigQuery.
As Google’s deadline approaches for the deletion of UA data (1st July 2024), our tool will become increasingly important for our clients who aim to preserve their UA data. More than just a bridge from UA to BigQuery, it promotes a more mindful and strategic approach to data preservation.
All companies we work with get access to this tool from today, so get in touch if you want to work with us and back up all of your key UA data while you still can!
Matthew Hooson

Subscribe to our newsletter:
Further reading

Dataform for BigQuery: A basic end-to-end guide
How to extract GA4’s event sequencing in BigQuery using the new batch fields